LLMの性能差がなくなった2026年、勝負を分けるのはハーネスである
2026年2月現在、主要なLLMの性能差はほぼなくなった。GPT-5.2、Claude Opus 4.5、Gemini 3 Pro、Llama 4——どれを選んでも「十分に賢い」。では何が差を生むのか。それは**ハーネス**、つまりモデルを包む仕組みの設計である。
この記事では、LLMをまだ本格的に活用していないエンジニア向けに、「ハーネスとは何か」「なぜ今重要か」を概念構造として整理する。
LLMの現在地:性能は均衡した
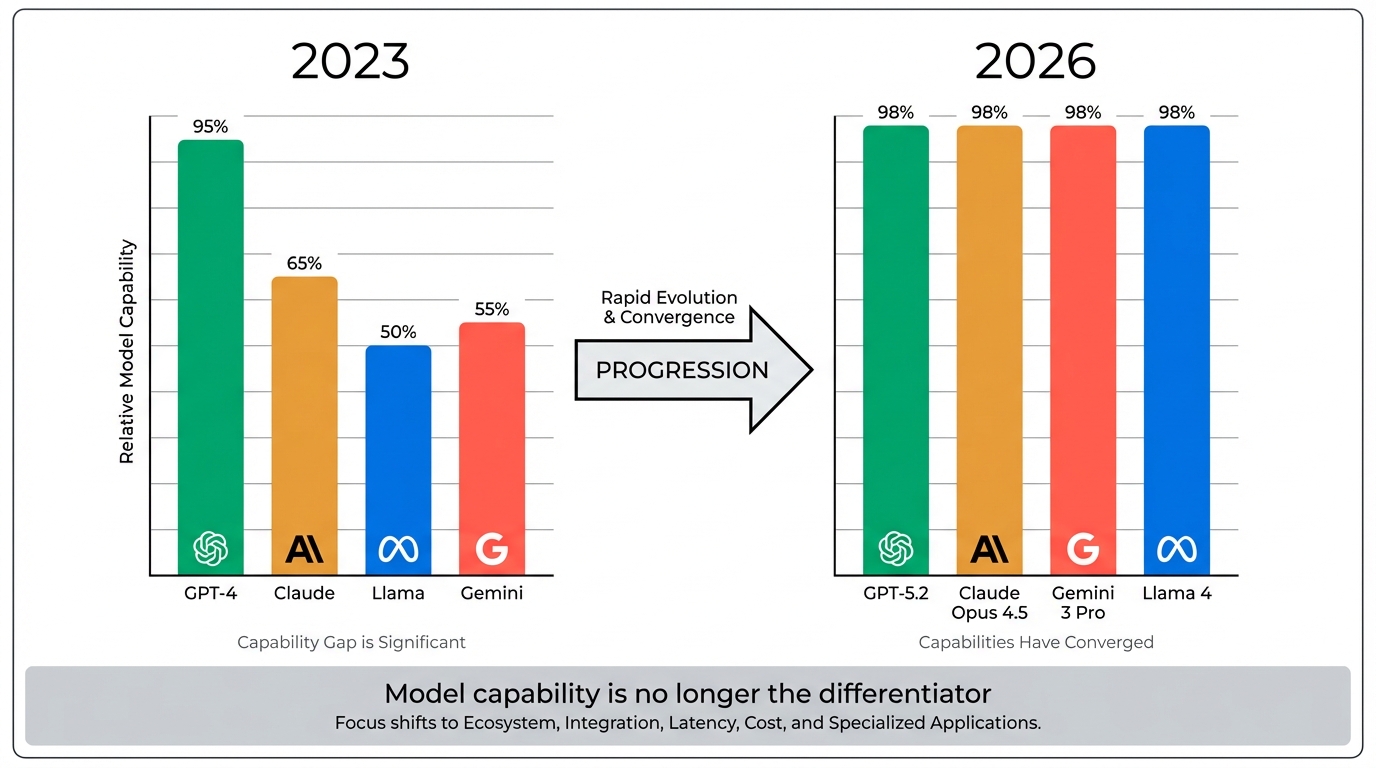
2023年、GPT-4の登場は衝撃だった。他のモデルとの性能差は歴然としており、「どのモデルを使うか」がそのままアウトプットの質を決めた。
2026年の状況はまるで違う。
| モデル | 提供元 | 数学ベンチ(AIME 2025) | コーディング(SWE-bench) |
|---|---|---|---|
| GPT-5.2 | OpenAI | 100% | — |
| Claude Opus 4.5 | Anthropic | — | 80.9% |
| Claude Sonnet 4.5 | Anthropic | 100%(ツール使用時) | — |
| Gemini 3 Pro | — | — | |
| Llama 4 Maverick | Meta | — | — |
ベンチマーク上の数値だけでなく、実務での体感としても「モデルを変えたら劇的に良くなった」という場面は減っている。モデル単体の性能は、もはや決定的な差別化要因ではない。
では、何が差を生むのか?
ハーネスとは何か
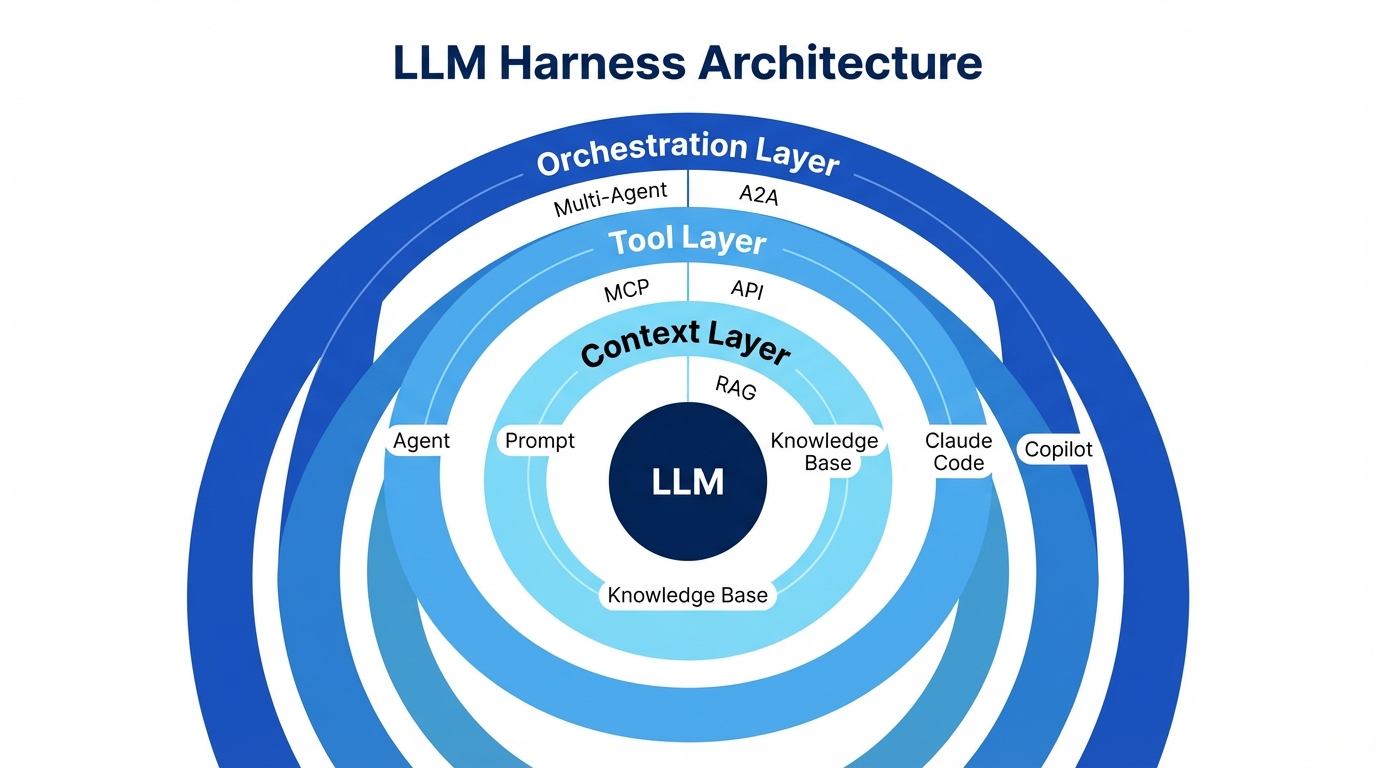
「ハーネス」とは、LLMを実用的に機能させるための周辺の仕組み全体を指す。馬に例えるなら、馬(LLM)がどれだけ速くても、手綱や鞍(ハーネス)がなければ乗りこなせない。
素のLLMは「賢いが文脈を知らない存在」だ。プロジェクトの構造も、チームの規約も、過去のやり取りも知らない。ハーネスは、この「文脈の欠如」を埋める仕組みである。
ハーネスは4つの層で構成される。
ハーネスの4層構造
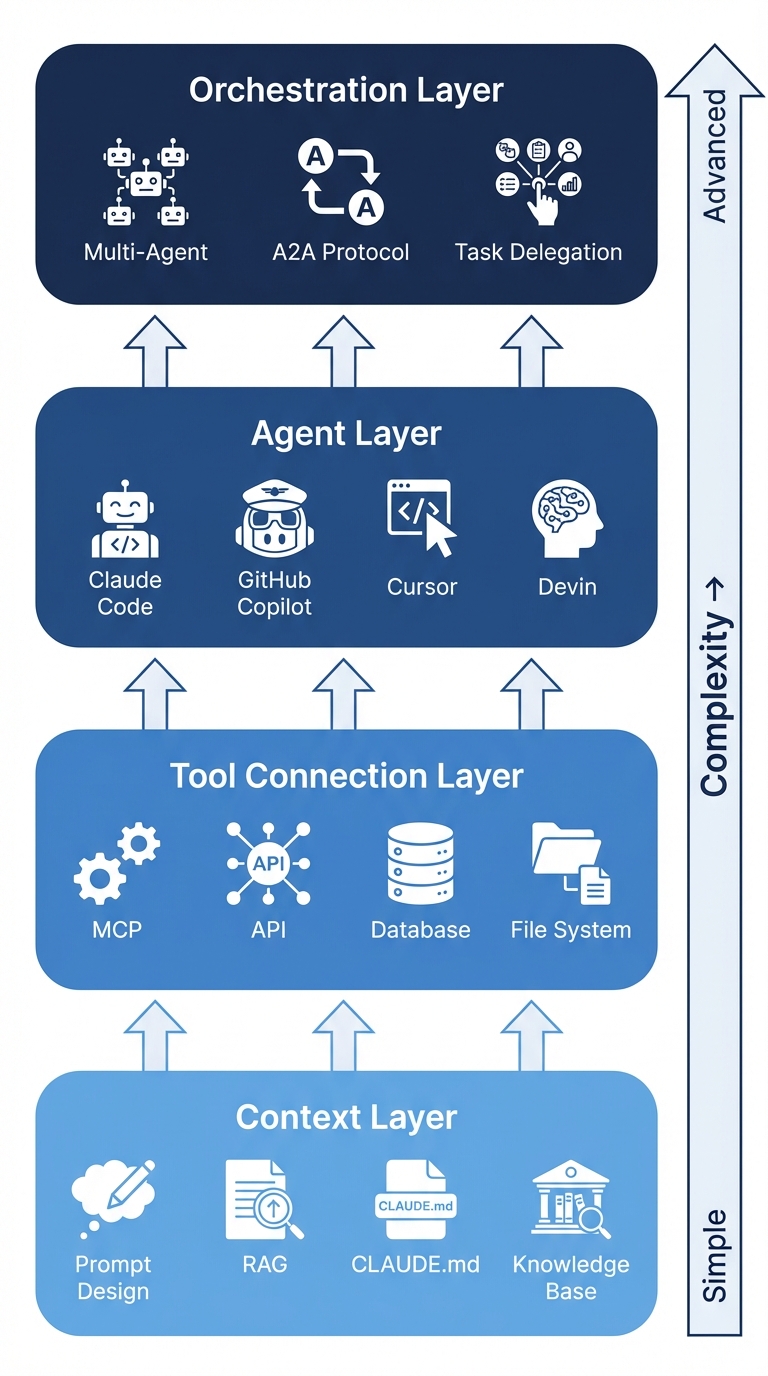
下の層ほど導入が簡単で、上の層ほど高度になる。重要なのは、下の層がしっかりしていないと上の層が機能しないということだ。
第1層:コンテキスト層
LLMに「何を知っておくべきか」を伝える層
LLMは毎回、白紙の状態から会話を始める。コンテキスト層は、LLMが仕事をするために必要な前提知識を注入する仕組みだ。
具体的な要素:
- システムプロンプト — LLMの振る舞いを定義する指示文。「あなたはTypeScriptのエキスパートです」のような役割設定
- CLAUDE.md / AGENTS.md — プロジェクトのルール・規約をファイルとして記述し、エージェントが自動で読み込む仕組み
- RAG(検索拡張生成) — 外部のドキュメントやコードを検索し、関連情報をLLMに渡す技術
- コンテキストウィンドウ — LLMが一度に処理できるテキスト量。2026年はLlama 4 Scoutの1,000万トークンを筆頭に劇的に拡大した
ないとどうなるか: LLMはプロジェクトの文脈を知らないので、一般的だが的外れな回答を返す。同じ説明を毎回繰り返す羽目になる。
第2層:ツール接続層
LLMが「外の世界と触れる」ための層
素のLLMはテキストを生成するだけで、ファイルを読んだり、データベースに問い合わせたり、APIを叩いたりはできない。ツール接続層は、LLMに「手足」を与える。
具体的な要素:
- MCP(Model Context Protocol) — Anthropicが策定し、現在はLinux Foundationが管理するオープン規格。LLMとツール(DB、ファイルシステム、API等)の接続を標準化する。USB-Cのように、一つの規格でさまざまなツールに繋げる
- Function Calling — LLMが「この関数を呼びたい」と宣言し、アプリケーション側が実行する仕組み
- APIインテグレーション — Slack、GitHub、Jiraなど外部サービスとの連携
ないとどうなるか: LLMの回答をコピペして手動で実行する、という「人間がグルー(接着剤)になる」状態。これでは自動化の恩恵を受けられない。
第3層:エージェント層
LLMが「自分で考えて動く」ための層
ツール接続層が「手足」なら、エージェント層は「意思決定」を担う。LLMがタスクを分解し、必要なツールを選び、結果を判断して次のアクションを決める——この自律的なループがエージェントだ。
具体的な要素:
- Claude Code — Anthropicの公式CLI。コードベースを理解し、実装・テスト・デバッグを自律的に実行する
- GitHub Copilot — IDE統合型。Agent Modeでファイル編集・ターミナル操作を自律実行
- Cursor — VS Codeフォーク。Composerモードで複数ファイルの同時編集が可能
- Devin — 最も自律性の高いコーディングエージェント。月額$20で利用可能に
ないとどうなるか: LLMとの対話は「一問一答」に留まる。複数ステップの作業は人間が分解・管理する必要がある。
第4層:オーケストレーション層
複数のエージェントが「協調して動く」ための層
1つのエージェントでは手に余る大きなタスクを、複数のエージェントに分担させる仕組み。現時点ではまだ発展途上だが、急速に整備が進んでいる。
具体的な要素:
- サブエージェント — メインエージェントが子エージェントを起動し、部分タスクを委譲する構造
- A2A Protocol(Agent2Agent Protocol) — Googleが策定したエージェント間通信の標準規格。異なるベンダーのエージェント同士が協調できる
- エージェントオーケストレーション — 複数エージェントの実行順序・依存関係・結果の統合を管理する仕組み
ないとどうなるか: 大規模タスクを1つのエージェントに任せると、コンテキストが溢れてミスが増える。人間が手動でタスクを分割・統合する必要がある。
ハーネスで何が変わるか
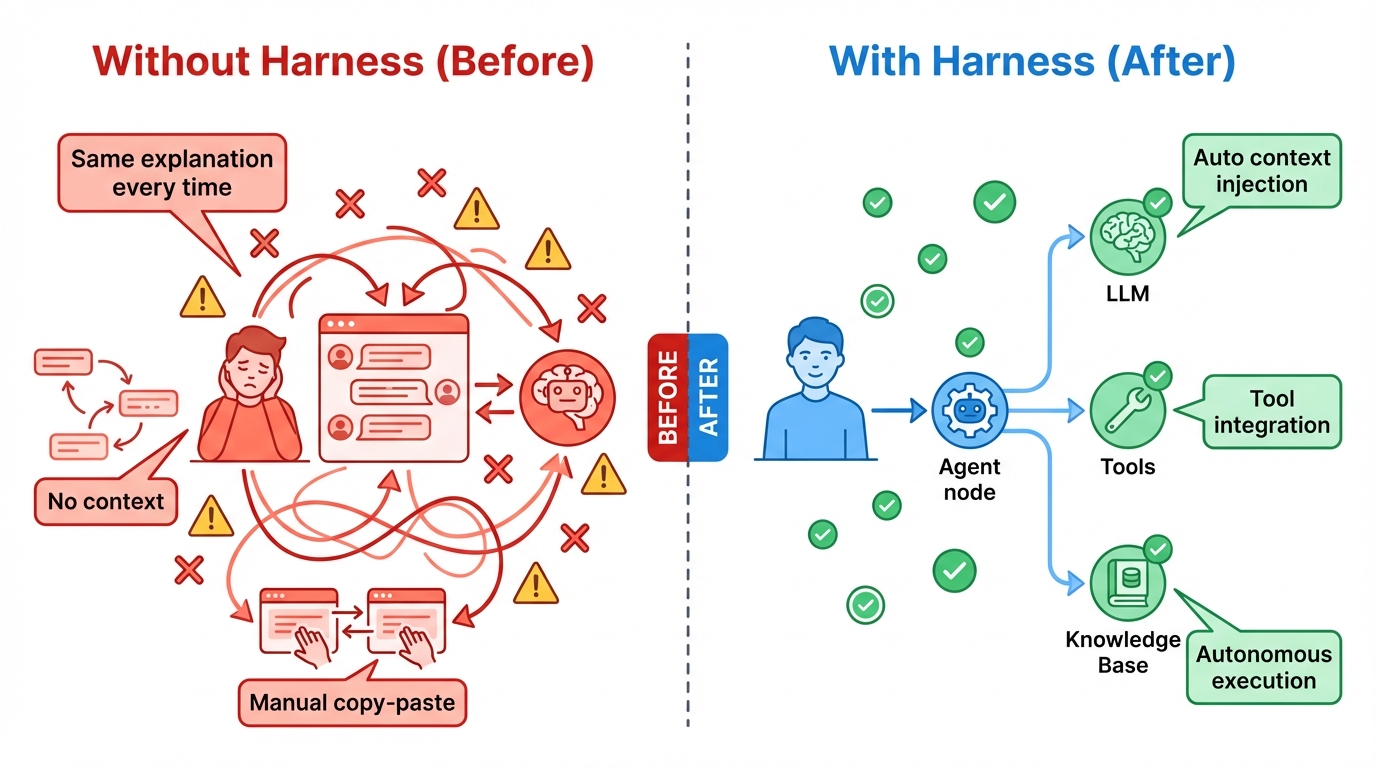
同じLLMを使っていても、ハーネスの有無で体験はまったく異なる。
| ハーネスなし | ハーネスあり | |
|---|---|---|
| コンテキスト | 毎回プロジェクト構造を説明 | CLAUDE.mdから自動読み込み |
| ツール連携 | LLMの出力を手動コピペ | MCPでDB・API直接操作 |
| タスク実行 | 一問一答の繰り返し | エージェントが自律的に実装 |
| 大規模作業 | 人間がタスク分割・管理 | サブエージェントに自動委譲 |
重要なのは、上位の層は下位の層に依存するということだ。エージェント(第3層)がうまく動くには、適切なコンテキスト(第1層)とツール接続(第2層)が前提になる。逆に言えば、第1層のコンテキスト設計だけでも、LLMの出力品質は劇的に向上する。
エンジニアが今日から始められること
4層すべてを一度に導入する必要はない。下の層から順に積み上げていくのが現実的だ。
ステップ1:コンテキスト層から始める
プロジェクトのルートにCLAUDE.mdやAGENTS.mdを置き、以下を記述する:
- プロジェクトの概要と技術スタック
- コーディング規約(命名規則、ディレクトリ構造)
- よく使うコマンド(ビルド、テスト、デプロイ)
これだけで、LLMの回答精度は格段に上がる。
ステップ2:ツール接続を試す
MCPサーバーを1つ導入してみる。ファイルシステムやGitHubとの接続から始めるのが取り組みやすい。
ステップ3:エージェントを導入する
Claude CodeやGitHub Copilot Agent Modeを使い、「Issue → 実装 → テスト → PR」の一連の流れをエージェントに任せてみる。最初は小さなタスクから。
ステップ4:必要に応じてオーケストレーションへ
複数の独立したタスクを並列実行したい場面が出てきたら、サブエージェント構成やA2Aプロトコルの検討を始める。
2026年のAI活用において、「どのモデルを使うか」はもはや最重要の問いではない。モデルをどう包むか——ハーネスの設計が、エンジニアとしての生産性を左右する時代になった。幸い、ハーネスの構築は今日からでも始められる。まずはコンテキスト層から、一歩ずつ積み上げていけばいい。
抽出された概念
- ハーネス - LLMを実用的に機能させる周辺の仕組み全体(4層構造)
- LLMコモディティ化 - 主要LLMの性能差が縮小し「どう使うか」が差別化要因になる現象